Construct Test Design Assess Test Adequacy Execute the Test
Design of Experiments
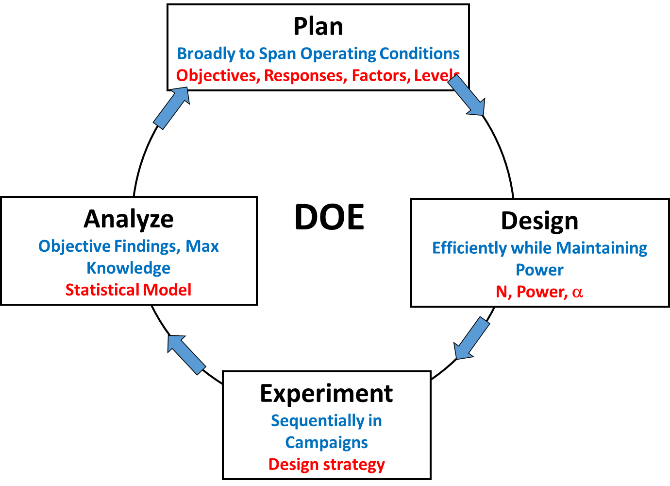
Design of Experiments (DOE) is a structured and purposeful approach to test planning. It is defined as a test or series of tests in which purposeful changes are made to the input variables in order to observe an outcome, which will be determined by a statistical analysis. (The term "test" is used throughout this site and it includes experiments as well as other design strategies). A designed test is a test or test program that is planned specifically to determine the effects of factors (also called Independent Variables) or their interactions on one or more measured responses (also called Dependent Variables). The purpose of a designed test is to ensure that the right types and amounts of data are available to answer the questions of interest while defining risks to support with statistically based decisions. After testing is completed and data collected, DOE will provide quantifiable, statistically defensible conclusions about system performance. The general steps are:- Define goal(s) of the test
- Identify dependent response variables that will address goal
- Identify independent variables (Factors & Factor Levels)
- Determine any testing constraints (e.g., lack of randomization, infeasible factor combinations)
- Select experimental design and sample size to control decision risks
- Prepare design in execution order and conduct test
- Analyze data, validate statistical model with check points as desired
- Draw conclusions and, if incomplete, redesign the test based on knowledge gained
 Benefits of DOE
DOE provides objective methods for assessing test adequacy by not only quantifying how much testing is enough, but also where in the operational space the test points should be placed. DOE also provides an analytical trade-space between test resources and risk, ensuring that tests are adequate to answer important questions.
A test design is a blueprint that describes factors and levels and how much testing is needed across the factors and levels of your test. A design will tell you what kind of information you can expect from your results, help you determine whether the test is affordable, and bring your attention to special considerations and decisions you may need to make. Careful design ensures you are answering the question you originally set out to ask.
Design of Experiments (DOE) is an exceptionally useful tool that guides test design. DOE is a field specifically concerned with the scientific and structured approach to test planning. It helps evaluators choose the right type and size of test to adequately cover the selected factors and levels and also provides an analytical basis for assessing test adequacy. This results in defensible test designs and results. Several foundational principles of DOE are critical to quality design and can be read about here.
The design you choose directly correlates to the question you wish to answer and the analysis you will use. There are many kinds of designs that serve different purposes and answer different questions. There are, however, general questions or test goals that can help narrow the possible design choices. The goals below have corresponding designs that are commonly used to address them.
General Test Goals and Corresponding Common Designs
[table id=5 /]
Benefits of DOE
DOE provides objective methods for assessing test adequacy by not only quantifying how much testing is enough, but also where in the operational space the test points should be placed. DOE also provides an analytical trade-space between test resources and risk, ensuring that tests are adequate to answer important questions.
A test design is a blueprint that describes factors and levels and how much testing is needed across the factors and levels of your test. A design will tell you what kind of information you can expect from your results, help you determine whether the test is affordable, and bring your attention to special considerations and decisions you may need to make. Careful design ensures you are answering the question you originally set out to ask.
Design of Experiments (DOE) is an exceptionally useful tool that guides test design. DOE is a field specifically concerned with the scientific and structured approach to test planning. It helps evaluators choose the right type and size of test to adequately cover the selected factors and levels and also provides an analytical basis for assessing test adequacy. This results in defensible test designs and results. Several foundational principles of DOE are critical to quality design and can be read about here.
The design you choose directly correlates to the question you wish to answer and the analysis you will use. There are many kinds of designs that serve different purposes and answer different questions. There are, however, general questions or test goals that can help narrow the possible design choices. The goals below have corresponding designs that are commonly used to address them.
General Test Goals and Corresponding Common Designs
[table id=5 /]
Overview of Common Designs
Factorial: Factorial designs include at least two factors and examine the combinations of each level. This combination allows the evaluator to determine the impact of each factor as well as whether one factor influences the impact of another factor on the test outcome. They are highly efficient and informative designs, though potentially prohibitively costly when many factors are involved (e.g., >4). For this reason, factorial designs are more common in developmental than operational testing scenarios, or whenever there are relatively few factors in the design. Follow the link for more detail on designing a factorial test as well as variations and advanced designs. For example, a 22 factorial design has 2 factors (lets say Temperature and Weather) with 2 levels of each factor (Temperature: Hot/Cold; Weather: Rainy/Dry) and would include test runs conducted under Hot and Rainy, Hot and Dry, Cold and Rainy, and Cold and Dry conditions. These test conditions will likely also be replicated. Fractional Factorial: These variations of full factorial designs do not require all combinations of factor levels to be included in the test, and include only a fraction of the test points that would be in a full factorial. They provide information on the main effects of each factor, and some information about how the factors interact. Fractional Factorial designs are a popular choice for defense system testing. Response Surface Designs: Response Surface Designs are a collection of designs that spread test points to collect data throughout the experimental region such that a more detailed model of the pattern of responses can be ascertained. They are used to locate where in the design space (or under what conditions) responses are optimal, and often to "map" a system's performance across a variety of conditions. This often involves the inclusion of higher order models that can estimate curves instead of monotonic linear effects. These designs also allow estimates of lack of fit and experimental error by adding center points, replications, and axial runs to 2k factorial or fractional factorial base designs. Optimal Designs: Optimal designs are constructed by computers using algorithms that modify test point placement until some criterion is maximized, or the design is optimal in terms of that specific criterion (i.e., optimality criteria). That is, the evaluators may want to generate a model that produces uniform predictions/minimal prediction variance, or that has minimal variation in model parameters. Optimal designs are often used when constraints prevent the use of standard designs (e.g., cannot test at extremes one or more factors; Cannot place test points due to sample size limitations). Evaluators input what model parameters they would like to estimate and how many runs are available, and software such as JMP or Minitab generates a design specifying the ideal placement of these test points. Experimental Campaign Sequential Designs: Experimental campaigns (often simply referred to as sequential designs) stand in contrast to "one-shot" designs and employ a series or sequence of smaller tests. The goal is to learn from one test and modify subsequent tests based on this information. Results from preliminary tests may lead the evaluator to drop or add factors, modify the levels of a factor, create more precise response variable measures, etc. Point-by-Point Sequential Design: A second form of sequential design is used in ballistic resistance testing. These designs sequentially employ sensitivity tests to estimate the probability that a projectile will perforate a surface as a function of factors such as velocity and angle. Evaluators employing these tests commonly look for velocity at which a projectile has a 50% probability of penetrating a surface (V50). For example, projectile velocity is adjusted for each sequential shot until stopping criteria is met (e.g., 3 perforations and 3 non-perforations are recorded within a specific velocity range). One particular sequential method - the Three-Phase Optimal Design (3POD) - and an application to generate 3POD response curves are presented here.
Issues Impacting Design Choice
In selecting your design, it is important to know that there are no one-size fits all designs and that you must tailor any design to fit your specific test circumstances. The following are common issues that impact test designs and should be carefully considered before moving on to execute your design. Many design modifications exist to accommodate these issues. Nature of Factors: How many factors does your design include? Will you test over the entire range of each factor? What are the regions of interest? Answering these questions determines your experimental region or design space and indicates where you may want to place test points. Operational Realism: Having a theoretical justification for observing an extreme factor level or certain condition does not mean doing so is feasible or recommended. The limitations of your system (e.g., cannot operate in severe heat), ethical considerations when including human subjects (e.g., unreasonably dangerous situations for operators), and other issues may force you to disallow certain combinations of factors and exclude these conditions from your test. Model Precision: If the goal of the test is to generate a detailed and precise model for predicting the effects of factors, you will likely include many more test points that cover more of the experimental region and also replicate several or all test points. Test Resources: Changing factors can often be costly or impractical, especially when factors are hard to change. Additionally, resource limitations may prevent you from adding all of the test points you would like or need for a classical design.
Advanced Tools and Design Augmentation
To address the issues mentioned above, classical designs can be modified in several ways. Common modification techniques and their ramifications are described here. Add Center Points: Center points are addition test runs placed in the middle of the design space, or at moderate, central levels of each factor. These additional test points allow for more precise predictions and detailed information on test performance, such as whether nonlinear trends exist. Disallow Combinations: When certain conditions are not run because of various constraints, that combination of factor levels is said to be disallowed. For example, nature may prevent the combination of high temperature runs at night. This can result in fractional factorial designs, as temperature and day/night cannot be crossed at the levels of hot and night. The evaluator loses the ability to fully estimate interaction terms involving these factors, but other information is salvaged by maintaining a portion of the factor combinations. Restrict Randomization: When factors are hard to change, or you are only interested in testing at one level of the factor, you might decide not to randomize the order of runs for these levels. One option, blocking, consists of testing at only one level of the factor and is often used to reduce the noise or error known to be associated with a factor. For example, if two operators are available for a test, but using both operators would introduce unwanted variability, the evaluator might block operator variability by having only one operator run all test runs. If the evaluator still wants to learn about the impact of a factor, but it is hard to change the factor from one level to another, split-plot designs can be employed. In split-plot designs, rather than randomly alternating levels of the hard to change factor, multiple runs are conducted at the first level and then the factor level is changed and several more runs are executed. Split-plot designs require special consideration for their analysis. The videos linked in the side bar explain split-plots and analysis implications in greater detail.
